
In a world where data-driven decision-making is critical, the tools we use to process and retrieve information must evolve. While Retrieval Augmented Generation (RAG) has been a key player in combining generation with retrieval, Cache Augmented Generation (CAG) is stepping in as a promising alternative. Let’s dive into these methods, understand their mechanics, and see why augmentation through caching might be the next leap forward.

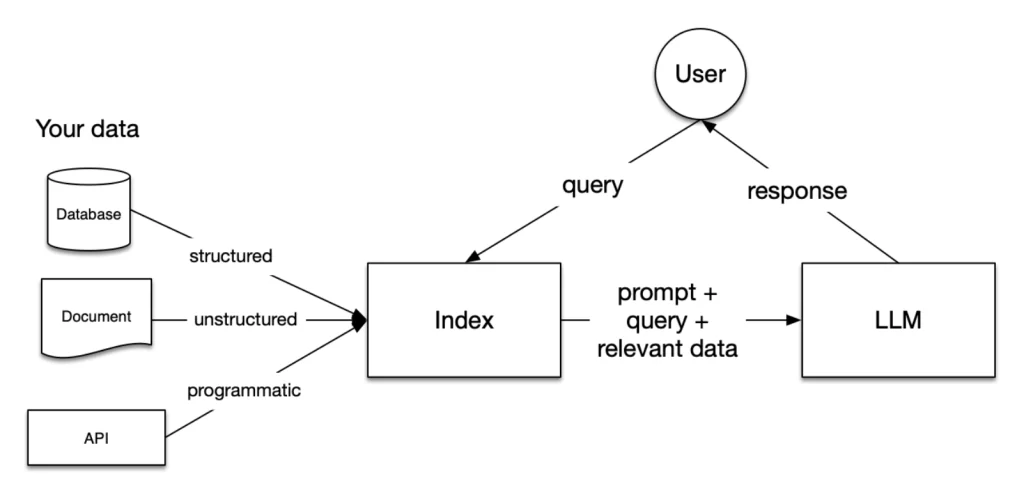
What Is RAG?
Retrieval Augmented Generation (RAG) is a framework that combines retrieval mechanisms with generative models. It fetches relevant data from external sources to enhance the model’s response. RAG strengthens generative outputs by integrating real-time, factual information from a knowledge base.
How Traditional RAG Works
Query Input: A user inputs a query.
Retrieval: The system searches a database, knowledge base, or indexed documents for relevant information.
Generation: A generative model uses the retrieved information to generate a response that is both informed and contextually appropriate.
Pros of RAG
Context-Awareness: Can use updated, domain-specific information.
Scalability: Works well with large datasets.
Factual Accuracy: Reduces hallucinations by incorporating real data.
Cons of RAG
Latency: Dependence on retrieval can slow down responses.
Dependency on External Sources: Performance relies heavily on the quality of the indexed data.
Complexity: Integrating retrieval and generation requires additional engineering efforts.
Examples of RAG
Customer Support: A chatbot retrieves product specifications from a company’s database to answer warranty-related questions.
Legal Assistance: A legal AI assistant fetches clauses from case law or statutes to provide contextually accurate advice.
Medical Diagnosis: A health app retrieves recent studies or drug information to support its recommendations.
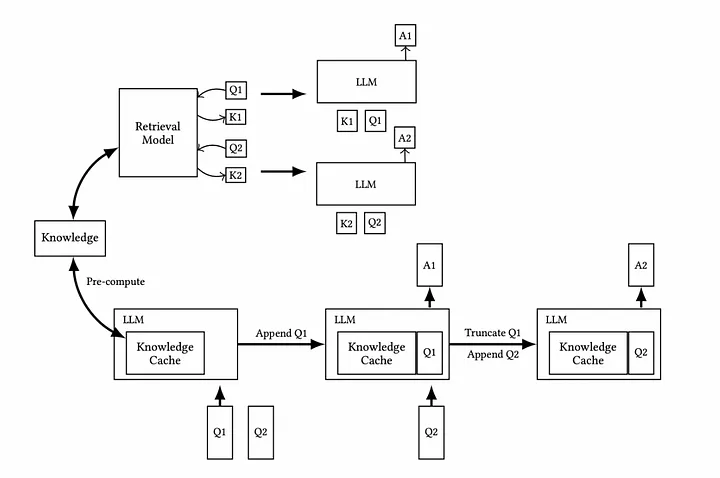
What Is CAG?
Cache Augmented Generation (CAG) takes a slightly different approach. Instead of relying solely on live retrieval from external databases, CAG leverages an internal cache. This cache is a pre-compiled, curated set of relevant information frequently used by the generative model.
How CAG Works
Query Input: A user submits a query.
Cache Check: The system checks its internal cache for relevant information.
Augmentation: Cached data is combined with generative processes to create a response.
Fallback Mechanism: If the cache lacks the needed data, the system can either retrieve it externally or update the cache for future us.
Pros of CAG
Speed: Accessing cached data is faster than retrieving from an external source.
Control: The cache can be tailored to prioritize accuracy and relevance.
Resource Efficiency: Reduces dependency on external systems.
Cons of CAG
Limited Scope: A cache might miss out on real-time or dynamic information.
Maintenance Overhead: Requires regular updates to keep the cache relevant.
Examples of CAG
E-Learning: An educational platform uses cached course content to answer frequently asked questions quickly.
Technical Support: A tech helpdesk system uses a preloaded cache of troubleshooting guides to provide instant answers.
Content Personalization: A streaming platform’s recommendation system leverages a cache of user preferences to generate suggestions with minimal delay.
Knowledge Sharing: An internal company chatbot uses a curated cache of policies and procedures to respond to employee queries.
Case Studies
RAG in Action
Financial News Aggregator Imagine a platform like Bloomberg, relied upon by financial analysts and traders worldwide. Such a system employs RAG to fetch live updates from stock exchanges, combining these real-time data points with predictive models. For instance, when a user queries the impact of a specific policy change, the RAG model retrieves the latest stock market movements, relevant financial reports, and expert opinions from its indexed databases. This ensures the generated insights are accurate, up-to-date, and actionable within seconds, making it indispensable for high-stakes financial decisions.
Travel Assistance Platforms like Expedia integrate RAG to provide real-time travel solutions. Picture a traveler searching for last-minute flights. The system retrieves updated flight schedules, availability, and pricing from multiple airline databases and integrates this with user preferences such as layover durations or budget limits. The result? A personalized and real-time travel itinerary that helps users make informed booking decisions instantly.
Medical Diagnostics A healthcare assistant powered by RAG enhances the precision of medical diagnostics. When a physician queries about the latest treatments for a rare condition, the system retrieves recent clinical trials, drug approvals, and medical journal articles. By integrating this dynamic, real-time data into its response, the assistant provides actionable insights that empower healthcare professionals to deliver evidence-based care, ultimately improving patient outcomes.
CAG in Action
Corporate Helpdesk In a large enterprise with thousands of employees, a CAG system can revolutionize internal support. For example, an employee queries about how to reset their email password. The system instantly retrieves the relevant troubleshooting guide from its preloaded cache of IT resources. By avoiding live retrieval and leveraging curated, frequently accessed documents, the helpdesk ensures lightning-fast response times while reducing server loads during peak query hours.
Online Education Consider an e-learning platform like Coursera, where students frequently ask similar questions about coursework. A CAG system preloads answers to common queries such as “What is the deadline for this assignment?” or “How can I access supplementary materials?” into its cache. This allows the platform to deliver immediate assistance, ensuring a smooth and frustration-free learning experience for students.
Customer Support for E-Commerce Imagine a retailer like Amazon deploying a CAG-powered chatbot for its customer service. When users inquire about order tracking, refund policies, or product specifications, the system draws from a preloaded cache of FAQs and policy documents. By bypassing external data retrieval, the chatbot delivers instant responses, enhancing customer satisfaction while streamlining support operations for repetitive, high-volume queries.
Why RAG Is Not Enough
While RAG has been instrumental in bridging the gap between retrieval and generation, it falls short in certain scenarios:
Latency: Real-time retrieval adds a noticeable delay.
System Failures: Dependence on external sources can introduce downtimes.
Overhead: Continuous retrieval adds computational costs.
These limitations create a gap for systems that prioritize speed and control, which CAG aims to address by leveraging cached augmentation.

When to Choose RAG or CAG
Best Cases for RAG
RAG is ideal for scenarios where up-to-date and dynamic information is crucial or when dealing with expansive and varied data sources. Here are detailed examples:
Real-Time, Dynamic Data Needs: Applications like financial systems that provide real-time updates on stock prices, currency exchange rates, or breaking news require RAG. These systems fetch the most recent data from external sources to deliver accurate, time-sensitive responses.
Extensive Knowledge Bases: RAG benefits legal research platforms or academic tools that search vast databases, such as case law, statutes, or research papers. The ability to pull specific details from large, diverse datasets ensures comprehensiveness and relevance.
Dynamic Question Answering: Customer-facing systems like travel booking assistants that rely on up-to-the-minute flight schedules, weather conditions, or hotel availability exemplify where RAG shines by retrieving fresh, situational data.
Best Cases for CAG
CAG is more suitable for environments requiring quick, repetitive responses or where the scope of information is stable and well-defined. Examples include:
Repetitive Queries: Customer service systems often encounter frequently asked questions, such as refund policies or troubleshooting steps. By using a curated cache, these systems can provide consistent and instant responses, reducing latency and improving user experience.
Low-Latency Applications: In scenarios like live technical support, users expect immediate solutions. A CAG system preloaded with a cache of common troubleshooting guides ensures that help is delivered instantly, without relying on real-time retrieval.
Internal Knowledge Systems: For companies managing internal chatbots or knowledge-sharing platforms, a CAG approach can efficiently respond to employee queries about standard procedures, benefits, or HR policies using a pre-curated cache.
Educational Platforms: Platforms offering e-learning resources can use CAG to quickly answer questions about course content, providing a seamless experience for learners without delays caused by external data retrieval.
Hybrid Approach: Combining RAG and CAG
A hybrid system can utilize both approaches by prioritizing cached data for frequent queries and returning to retrieval for dynamic or less common requests. This ensures both speed and breadth.
Best Practices
Cache Management: Regularly update and validate the cache for accuracy.
Fallback Strategy: Implement a seamless mechanism to switch between cache and retrieval.
Monitoring: Continuously evaluate the system’s performance to balance speed and accuracy.
Future Directions
Adaptive Caching: Dynamic updates based on query patterns.
Decentralized Augmentation: Distributed caches for scalable systems.
Enhanced Hybrid Models: Better integration of RAG and CAG for optimized workflows.
How Zaytrics Will HelpYou?
At Zaytrics, we understand the need for robust, scalable, and high-quality AI agents tailored to your business requirements. Whether you need near real-time answers or rely on internal documents for repetitive tasks, we can help you design and implement an agents that perfectly aligns with your goals.
CAG for Internal Data Needs: If your business relies heavily on internal documentation or frequently asked questions, CAG provides an efficient and fast solution. By leveraging a curated cache, we ensure your system delivers instant responses without relying on external sources.
RAG for Real-Time Accuracy: For applications like news updates, stock market analysis, or dynamic customer queries, RAG ensures your system retrieves the most current and accurate information from external knowledge bases.
Speed Differences: CAG is significantly faster as it accesses preloaded data directly from a cache, ideal for low-latency use cases. RAG, while slower due to real-time retrieval, excels in delivering up-to-date information, making it suitable for dynamic environments.
Hybrid AI Agent: At Zaytrics, we can also build hybrid AI agents that combine the strengths of both RAG and CAG. These solutions prioritize cached data for speed while allowing retrieval for dynamic or uncommon requests, ensuring the best of both worlds.
With our expertise, we help you achieve the perfect balance of scalability, performance, and quality in your AI systems.
Feel free to reach out for more details. Contact Zaytrics Today!
Conclusion
Cache Augmented Generation (CAG) is a powerful complement to Retrieval Augmented Generation (RAG), addressing gaps in latency and control. While RAG excels in dynamic, real-time scenarios, CAG offers speed and efficiency for repetitive tasks. By understanding their unique strengths and combining them thoughtfully, we can build robust and responsive systems. Augmentation is the key to unlocking these possibilities.


